
반응형
- 참고 : 이수안컴퓨터연구소
Autograd(자동미분)
torch.autograd 패키지는 Tensor의 모든 연산에 대해 _\_자동 미분** 제공
이는 코드를 어떻게 작성하여 실행하느냐에 따라 역전파가 정의된다는 뜻
backprop를 위해 미분값을 자동으로 계산
requires_grad 속성을 True로 설정하면, 해당 텐서에서 이루어지는 모든 연산들을 추적하기 시작
기록을 추적하는 것을 중단하게 하려면, .detach()를 호출하여 연산기록으로부터 분리
a = torch.randn(3, 3)
a = a* 3
print(a)
print(a.requires_grad)
>> tensor([[ 3.9995, -0.8653, -3.2425],
[ 3.2839, 1.6168, -2.2379],
[ 1.7515, -2.3401, -3.7680]])
False- requires_grad_(...)는 기존 텐서의 requires_grad 값을 바꿔치기(in-place)하여 변경
- grad_fn: 미분값을 계산한 함수에 대한 정보 저장 (어떤 함수에 대해서 backprop 했는지)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b)
print(b.grad_fn)
>> a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b)
print(b.grad_fn)기울기(Gradient)
x = torch.ones(3, 3, requires_grad=True)
print(x)
>> tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], requires_grad=True)
y = x+5
print(y)
>> tensor([[6., 6., 6.],
[6., 6., 6.],
[6., 6., 6.]], grad_fn=<AddBackward0>)
z = y * y
out = z.mean()
print(z, out)
>> tensor([[36., 36., 36.],
[36., 36., 36.],
[36., 36., 36.]], grad_fn=<MulBackward0>) tensor(36., grad_fn=<MeanBackward0>)- 계산이 완료된 후, .backward()를 호출하면 자동으로 역전파 계산이 가능하고, .grad 속성에 누적됨
print(out)
out.backward()
>> tensor(36., grad_fn=<MeanBackward0>)- grad: data가 거쳐온 layer에 대한 미분값 저장
print(x)
print(x.grad) # 미분값
>> tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], requires_grad=True)
tensor([[1.3333, 1.3333, 1.3333],
[1.3333, 1.3333, 1.3333],
[1.3333, 1.3333, 1.3333]])
x = torch.randn(3, requires_grad = True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)
>> tensor([ 713.1057, 1177.7717, -494.0118], grad_fn=<MulBackward0>)
v = torch.tensor([0.1, 1.0, 0.0001], dtype = torch.float)
y.backward(v)
print(x.grad)
>> tensor([1.0240e+02, 1.0240e+03, 1.0240e-01])- with torch.no_grad()를 사용하여 기울기의 업데이트를 하지 않음
- 기록을 추적하는 것을 방지하기 위해 코드 블럭을 with torch.no_grad()로 감싸면 기울기 계산은 필요없지만, requires_grad=True로 설정되어 학습 가능한 매개변수를 갖는 모델을 평가(evaluate)할 때 유용
print(x.requires_grad)
print((x**2).requires_grad)
with torch.no_grad():
print((x**2).requires_grad)
>> True
True
False- detach(): 내용물(content)은 같지만 require_grad가 다른 새로운 Tensor를 가져올 때
print(x.requires_grad)
y = x.detach()
print(y.requires_grad)
print(x.eq(y).all())
>> True
False
tensor(True)자동 미분 흐름 예제
- 계산 흐름 a -> b -> c -> out
backward()를 통해 a <- b <- c <- out을 계산 하면

a = torch.ones(2,2)
print(a)
>> tensor([[1., 1.],
[1., 1.]])
a = torch.ones(2,2,requires_grad=True)
print(a)
>> tensor([[1., 1.],
[1., 1.]], requires_grad=True)
print(a.data)
print(a.grad) # 아직 계산한게 없음
print(a.grad_fn)
>> tensor([[1., 1.],
[1., 1.]])
None
None- b = a + 2
b = a+2
print(b)
>> tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)- c = b ** 2
c = b ** 2
print(c)
>> tensor([[9., 9.],
[9., 9.]], grad_fn=<PowBackward0>)
out = c.sum()
print(out)
>> tensor(36., grad_fn=<SumBackward0>)
print(out)
out.backward()
>> tensor(36., grad_fn=<SumBackward0>)- a의
grad_fn이 None인 이유는 직접적으로 계산한 부분이 없었기 때문
print(a.data)
print(a.grad)
print(a.grad_fn)
>> tensor([[1., 1.],
[1., 1.]])
tensor([[6., 6.],
[6., 6.]])
None
print(b.data)
print(b.grad)
print(b.grad_fn)
>> tensor([[9., 9.],
[9., 9.]])
None
print(out.data)
print(out.grad)
print(out.grad_fn)
>> tensor(36.)
None데이터 준비
- 파이토치에서는 데이터 준비를 위해 torch.utils.data의 Dataset과 DataLoader 사용 가능
- Dataset에는 다양한 데이터셋이 존재 (MNIST, FashionMNIST, CIFAR10, ...)
- Vision Dataset: https://pytorch.org/vision/stable/datasets.html
- Text Dataset: https://pytorch.org/text/stable/datasets.html
- Audio Dataset: https://pytorch.org/audio/stable/datasets.html
- DataLoader와 Dataset을 통해 batch_size, train 여부, transform 등을 인자로 넣어 데이터를 어떻게 load할 것인지 정해줄 수 있음
from torch.utils.data import Dataset, DataLoader- 토치비전(torchvision)은 파이토치에서 제공하는 데이터셋들이 모여있는 패키지
- transforms: 전처리할 때 사용하는 메소드 (https://pytorch.org/docs/stable/torchvision/transforms.html)
- transforms 에서 제공하는 클래스 이외는 일반적으로 클래스를 따로 만들어 전처리 단계를 진행
import torchvision.transforms as transforms
from torchvision import datasets- DataLoader의 인자로 들어갈 transform을 미리 정의할 수 있고, Compose를 통해 리스트 안에 순서대로 전처리 진행
- ToTensor()를 하는 이유는 torchvision이 PIL Image 형태로만 입력을 받기 때문에 데이터 처리를 위해서 Tensor형으로 변환 필요
mnist_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(1.0,))])
trainset = datasets.MNIST(root='/content',
train=True, download = True,
transform=mnist_transform)
testset = datasets.MNIST(root='/content',
train=False, download = True,
transform=mnist_transform)- DataLoader는 데이터 전체를 보관했다가 실제 모델 학습을 할 때 batch_size 크기만큼 데이터를 가져옴
train_loader = DataLoader(trainset, batch_size = 8, shuffle = True, num_workers = 2)
test_loader = DataLoader(testset, batch_size = 8, shuffle = False, num_workers = 2)
dataiter = iter(train_loader)
images, labels = dataiter.next()
images.shape, labels.shape
>> (torch.Size([8, 1, 28, 28]), torch.Size([8]))
torch_image = torch.squeeze(images[0])
torch_image.shape
>> torch.Size([28, 28])
figure = plt.figure(figsize = (12,6))
cols, rows = 4, 2
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(trainset), size=(1,)).item()
img, label = trainset[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(label)
plt.axis('off')
plt.imshow(img.squeeze(), cmap='gray')
신경망 구성
- 레이어(layer): 신경망의 핵심 데이터 구조로 하나 이상의 텐서를 입력받아 하나 이상의 텐서를 출력
- 모듈(module): 한 개 이상의 계층이 모여서 구성
- 모델(model): 한 개 이상의 모듈이 모여서 구성
torch.nn 패키지
- 주로 가중치(weights), 편향(bias)값들이 내부에서 자동으로 생성되는 레이어들을 사용할 때 사용 (weight 값들을 직접 선언 안함) 링크
import torch.nn as nn- nn.Linear 계층 예제
input = torch.randn(128, 20)
print(input)
m = nn.Linear(20, 30)
print(m)
output = m(input)
print(output)
print(output.size())
>> tensor([[-1.6431e-01, 2.4188e+00, -6.0349e-01, ..., 6.1271e-01,
1.3548e+00, -1.6134e+00],
[ 2.7471e-01, -1.3449e+00, 3.7916e-01, ..., -4.8053e-02,
-9.0114e-01, 1.3245e+00],
[ 4.7630e-01, -6.2055e-01, -6.0602e-02, ..., 1.3518e+00,
1.3581e+00, 2.4974e+00],
...,
[-1.9136e-03, -8.3295e-01, -2.6313e-01, ..., -1.9223e+00,
-1.3371e+00, -6.5886e-01],
[ 7.7946e-01, 2.0733e+00, -8.0232e-01, ..., 1.1952e+00,
2.9604e-01, -4.8862e-01],
[-8.4236e-01, -7.2081e-01, -5.2363e-01, ..., -2.9307e-01,
3.8436e-01, -4.5752e-01]])
Linear(in_features=20, out_features=30, bias=True)
tensor([[-0.4185, -0.6679, 0.9269, ..., 0.3681, -0.0172, -0.3034],
[ 0.5861, 0.4151, -0.9756, ..., -0.3040, -0.4421, -0.0847],
[ 0.3398, -0.1608, 0.2946, ..., 0.4408, 0.4359, -1.2890],
...,
[ 0.9922, 0.8995, -0.7543, ..., -0.9304, 0.3095, 1.0554],
[-0.3691, 0.4027, 0.7702, ..., 0.4750, -0.3637, 0.6345],
[ 0.0258, 0.2662, 0.9814, ..., -0.3012, -0.0100, 0.8502]],
grad_fn=<AddmmBackward0>)
torch.Size([128, 30]) - nn.Conv2d 계층 예시
input = torch.randn(20, 16, 50, 100)
print(input.size())
>> torch.Size([20, 16, 50, 100])
m = nn.Conv2d(16, 33, 3, stride=2)
m = nn.Conv2d(16, 33, (3, 5), stride=(2,1), padding=(4,2))
m = nn.Conv2d(16, 33, (3, 5), stride=(2,1), padding=(4,2), dilation=(3,1))
print(m)
>> Conv2d(16, 33, kernel_size=(3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
output = m(input)
print(output.size())
>> torch.Size([20, 33, 26, 100])컨볼루션 레이어(Convolution Layers)
- nn.Conv2d 예제
- in_channels : channel의 갯수
- out_channels : 출력 채널의 갯수
- kernel_size : 커널(필터) 사이즈
nn.Conv2d(in_channels=1, out_channels=20, kernel_size=5, stride=1)
>> Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
layer = nn.Conv2d(1, 20, 5, 1).to(torch.device('cpu'))
layer
>> Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))- weight 확인
weight = layer.weight
weight.shape
>> torch.Size([20, 1, 5, 5])- weight는 detach()를 통해 꺼내줘야 numpy()변환이 가능
weight = weight.detach()
weight = weight.numpy()
weight.shape
>> (20, 1, 5, 5)
plt.imshow(weight[0, 0, :, :], 'jet')
plt.colorbar()
plt.show()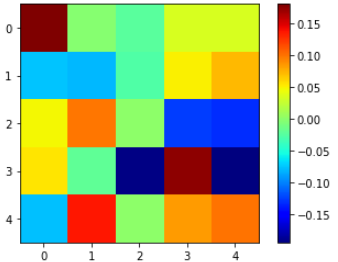
print(images.shape)
print(images[0].size())
input_image = torch.squeeze(images[0])
print(input_image.size())
>> torch.Size([8, 1, 28, 28])
torch.Size([1, 28, 28])
torch.Size([28, 28])
input_data = torch.unsqueeze(images[0], dim = 0)
print(input_data.size())
output_data = layer(input_data)
output = output_data.data
output_arr = output.numpy()
output_arr.shape
>> torch.Size([1, 1, 28, 28])
(1, 20, 24, 24)
plt.figure(figsize=(15,30))
plt.subplot(131)
plt.title('Input')
plt.imshow(input_image, 'gray')
plt.subplot(132)
plt.title('Weight')
plt.imshow(weight[0, 0, :, :], 'jet')
plt.subplot(133)
plt.title('Output')
plt.imshow(output_arr[0, 0, :, :], 'gray')
plt.show()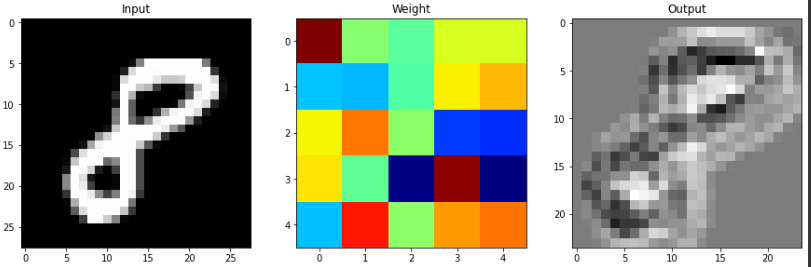
풀링 레이어(Pooling layers)
- F.max_pool2d
- stride
- kernel_size
- torch.nn.MaxPool2d 도 많이 사용
import torch.nn.functional as F
pool = F.max_pool2d(output, 2, 2)
pool.shape
>> torch.Size([1, 20, 12, 12])- MaxPool Layer는 weight가 없기 때문에 바로 numpy() 변환 가능
pool_arr = pool.numpy()
pool_arr.shape
>> (1, 20, 12, 12)
plt.figure(figsize=(10,15))
plt.subplot(121)
plt.title('Input')
plt.imshow(input_image, 'gray')
plt.subplot(122)
plt.title('Output')
plt.imshow(pool_arr[0, 0, :, :], 'gray')
plt.show() # 2 x 2 하나로 합쳐져서 해상도 줄어짐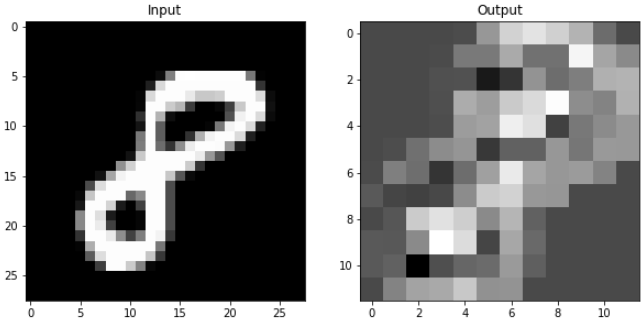
선형 레이어(Linear layers)
- 1d만 가능하므로 .view()를 통해 1d로 펼쳐줘야함
flatten = input_image.view(1, 28 * 28)
flatten.shape
>> torch.Size([1, 784])
lin = nn.Linear(784, 10)(flatten)
lin.shape
>> torch.Size([1, 10])
lin
>> tensor([[-0.0540, 0.1178, 0.4199, -0.0949, 0.3062, 0.5394, -0.2762, -0.1087,
0.2365, -0.1775]], grad_fn=<AddmmBackward0>)
plt.imshow(lin.detach().numpy(), 'jet')
plt.colorbar()
plt.show()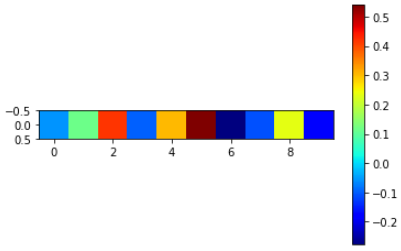
비선형 활성화 (Non-linear Activations)
F.softmax와 같은 활성화 함수 등
with torch.no_grad():
flatten = input_image.view(1, 28 * 28)
lin = nn.Linear(784, 10)(flatten)
softmax = F.softmax(lin, dim=1)
softmax
>> tensor([[0.1354, 0.1265, 0.0782, 0.1202, 0.0861, 0.0957, 0.0853, 0.0676, 0.1183,
0.0866]])
np.sum(softmax.numpy())
>> 1.0- F.relu
- ReLU 함수를 적용하는 레이어
- nn.ReLU로도 사용 가능
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # gpu check
inputs = torch.randn(4, 3, 28, 28).to(device)
inputs.shape
>> torch.Size([4, 3, 28, 28])
layer = nn.Conv2d(3, 20, 5, 1).to(device)
output = F.relu(layer(inputs))
output.shape
>> torch.Size([4, 20, 24, 24])- 신경망 종류
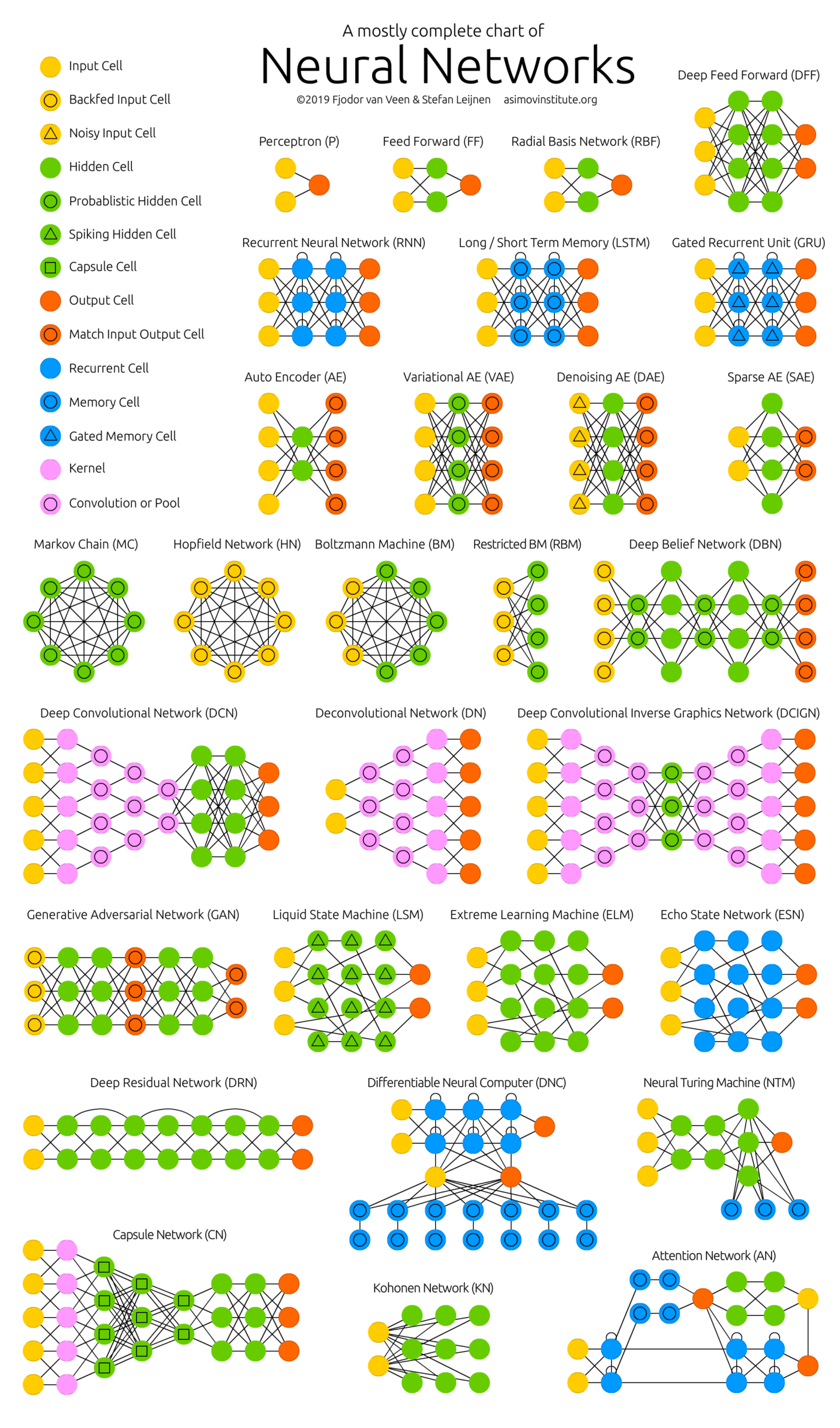
반응형
'Study > Self Education' 카테고리의 다른 글
| Pytorch 기본기 - 4 (0) | 2024.07.02 |
|---|---|
| Pytorch 기본기 - 3 (0) | 2024.07.02 |
| Pytorch 기본기 - 1 (0) | 2024.07.02 |
| 핸즈온 머신러닝 - 14 (0) | 2024.06.19 |
| 핸즈온 머신러닝 - 13 (0) | 2024.06.19 |