
- 참고 : 핸즈온 머신러닝 2판
심층 신경망 훈련하기
- 그레이디언트 소실 또는 그레이디언트 폭주 문제
- 대규모 신경망을 위한 훈련 데이터의 부족, 레이블 작업 비용 문제
- 훈련이 극단적인 시간 소요
- 수백만 개의 파라미터를 가진 모델은 훈련 세트에 과대적합될 위험이 존재
그레이디언트 소실과 폭주 문제
- 경사 하강법이 하위층의 연결 가중치를 변경하지 않은 채로 훈련되어 좋은 솔루션으로 수렴하지 못하는 상태를 그레이디언트 소실
- 그레이디언트가 점점 커져서 여러 층이 비정상적으로 큰 가중치로 갱신되어 알고리즘이 발산하는 상태를 그레이디언트 폭주
- 일반적으로 불안정한 그레이디언트는 심층 신경망 훈련을 어렵게 만듬
글로럿과 He 초기화
예측을 할 때는 정방향, 그레이디언트 역전파할 때는 역방향으로 양방향 신호가 적절하게 하는것이 그레이디언트 문제를 완화함
- 이를 위해서 각 층의 출력에 대한 분산이 입력에 대한 분산과 같아야 한다고 주장
- 역방향에서 층을 통과하기 전과 후의 그레이디언트 분산이 동일해야 한다고 주장
층의 입력과 출력 연결 개수(팬인, 팬아웃)가 같지 않다면 위의 두 가지 주장을 보장 할 수 없음
- 각 층의 연결 가중치를 무작위로 초기화 하여서 두 가지의 주장을 보안함
keras는 기본적으로 균등분포의 글로럿 초기화를 사용
- kernel_initializer="he_uniform" 혹은 kernel_initializer="he_normal" 로 바꾸어서 He 초기화 사용가능
keras.layers.Dense(10, activation="relu", kernel_initializer="he_normal")fan in 대신 fan out 기반의 균등분포 he 초기화를 사용하고 싶다면 Variance Scaling을 사용할 수 있음
init = keras.initializers.VarianceScaling(scale=2., mode='fan_avg', distribution='uniform') keras.layers.Dense(10, activation="relu", kernel_initializer=init)
수렴하지 않는 활성화 함수
활성화 함수를 잘못 선택하면 자칫 그레이디언트의 소실이나 폭주로 연결될수 있음
- 이전에는 대부분 생물학적 뉴런의 방식과 비슷한 시그모드 활성화 함수를 사용
- 현재는 생물학적 뉴런과 다른 활성화 함수가 훨씬 더 잘 작동함
Relu는 특정 양숫값에 수렴하지 않음, 계산속도 빠름
- dying Relu문제가 존재, 훈련하는 동안 일부 뉴런이 0이외의 값을 출력하지 않는 경우
- 훈련 세트에 있는 모든 샘플에 대해 입력의 가중치 합이 음수가 되면 뉴런이 죽게 됨
- 음수는 0으로 출력하기 때문
dying Relu 문제를 해결하기 위해 LeakyRelu와 같은 Relu 함수의 변종을 사용

- dying Relu 현상 발생시 일반적으로 0.01 기울기로 출력하기 때문에 기울기가 없어지지 않음
이외에도 기울기를 주어진 범위에서 무작위로 선택하고 테스트 시에는 평균을 사용하는 RRelu, 기울기가 훈련하는 동안 학습되는 PReLU도 존재
ELU
해당 활성화 함수는 모든 RelU 변종의 성능보다 높음
훈련 시간이 줄고 신경망의 테스트 세트 성능도 더 좋음

몇 가지 특성을 제외하면 ReLU와 매우 유사함
- 기울기가 음수일때 활성화 함수의 평균 출력이 0에 더 가까워 짐, 이를 통해 그레이디언트 소실 문제를 완화해줌
- 모든 구간에서 매끄럽게 경사 하강법의 속도를 높여줌
단점
- 지수함수를 사용하기 때문에 RelU나 다른 변종들보다 계산이 느리다는 점이 존재
SELU
- 스케일이 조정된 ELU 활성화 함수의 변종
- dense 연결 층만 쌓아서 신경망을 만들고 모든 은닉층이 SELU 활성화 함수를 사용한다면 네트워크가 자기 정규화 된다는 것을 발견
- 훈련하는 동안 각 층의 출력이 평균 0과 표준편차 1을 유지하는 경향이 존재
- 그레이디언트 소실과 폭주 문제를 막아 줌
- 자기 정규화가 발생하기 위한 몇가지 조건
- 입력 특성이 반드시 표준화 (평균 0 표준편차 1)
- 모든 은닉츠의 가중치는 르쿤 정규분포 초기화로 초기화 (keras에서는 kernel_initializer = "lecun_normal")
- 네트워크는 일렬로 쌓은 층으로 구성되어야 함 (스킵 연결과 같은 순차적이지 않는 구조는 안됨)
일반적으로 SELU > ELU > LeakyRelU > RelU > tanh 순서로 추천
- LeakyRelU 활성화 함수를 사용하려면 LeakyRelU층을 만들고 모델에서 적용하려는 층 뒤에 추가
model = keras.models.Sequential([
...
keras.layers.Dense(300, kernel_initializer="he_normal"),
keras.layers.LeakyReLU(alpha=0.2),
...
])- PReLU를 사용은 keras.layers.PReLU()로 사용
배치 정규화
- 그레이디언트 소실과 폭주 문제를 해결하기 위한 방법
- 각 층에서 두 개의 새로운 파라미터로 결과값의 스케일을 조정하고 이동
- 신경망의 첫 번째 층으로 배치 정규화를 추가하면 훈련세트를 표준화할 필요가 없음
- keras의 BatchNormalization층을 통해 수행
- 모든 신경망에서 배치 정규화가 성능을 크게 향상시킴
- 배치 정규화는 규제와 같은 역할을 수행해 다른 규제 기법의 필요성을 줄여 줌
- 단점
- 모델의 복잡성을 키움
- 시간소요가 큼
- 하지만 소요되는 시간이 결과적으로 수렴되는 시간이 빨라져서 상쇄
케라스로 배치 정규화 구현하기
은닉층의 활성화 함수 전이나 후에 BatchNormalization층을 추가하면 됨
예시
model = keras.models.Sequential([ keras.layers.Flatten(input_shape=[28, 28]), keras.layers.BatchNormalization(), keras.layers.Dense(300, activation="relu"), keras.layers.BatchNormalization(), keras.layers.Dense(100, activation="relu"), keras.layers.BatchNormalization(), keras.layers.Dense(10, activation="softmax") ])- 배치 정규화 층은 입력마다 4개의 파라미터

- 해당 파라미터는 역전파로 학습되지 않기 때문에 Non-trainable 파라미터
- 배치 정규화 층은 입력마다 4개의 파라미터
일반적으로 활성화 함수 이전에 배치 정규화 층을 추가하는 것이 좋음
배치 정규화 층은 입력마다 이동 파라미터를 포함하기 때문에 이전 층에서 편향을 뺄 수 있음 (use_bias=False)
model = keras.models.Sequential([ keras.layers.Flatten(input_shape=[28, 28]), keras.layers.BatchNormalization(), keras.layers.Dense(300, use_bias=False), keras.layers.BatchNormalization(), keras.layers.Activation("relu"), keras.layers.Dense(100, use_bias=False), keras.layers.BatchNormalization(), keras.layers.Activation("relu"), keras.layers.Dense(10, activation="softmax") ])axis라는 파라미터가 존재하는데 해당 파라미터는 정규화할 축을 결정
- 기본값은 -1 : 마지막 축을 정규화
- 입력 배치가 2D면 각 입력 특성이 배치에 있는 모든 샘플에 샘플에 대해 계산한 평균과 표준편차를 기반으로 정규화
일반적으로 모든 모델에서 BatchNormalization층이 생략되어 있다고 생각하면 됨
그레이디언트 클리핑
역전파될 때 일정 임곗값을 넘어서지 못하게 그레이디언트를 잘라내는 것, 이를 그레이디언트 클리핑
kears 에서 그레이디언트 클리핑 구현
optimizer = keras.optimizers.SGD(clipvalue=1.0)그레이디언트 벡터의 모든 원소를 -1.0과 1.0 사이로 클리핑 수행
- 손실의 모든 편미분 값을 -1.0에서 1.0으로 잘라냄, 임계값은 하이퍼파라미터로 튜닝할수 있음
- 그레이디언트 벡터의 방향을 바꿀 수 있음
- 그레이디언트 벡터 방향을 바꾸지 못하게 하기위해서는 clipvalue 대신 clipnorm을 지정하여 노름으로 클리핑 수행
사전훈련된 층 재사용하기
- 일반적으로 아주 큰 규모의 DNN을 처음부터 새로 훈련하는 것은 좋은 방법이 아님
- 이미 학습된 신경망을 찾고 해당 신경망의 하위층을 재사용하는 것이 좋음, 이를 전이 학습 이라고 함
- 일반적으로 원본 신경망의 출력층을 변경함
- 재 사용할 층의 개수를 정하는 것도 중요함
케라스를 사용한 전이 학습
- 출력층만 제외하고 모든 층 재사용
model_A = keras.models.load_model("my_model_A.h5")
model_B_on_A = keras.models.Sequential(model_A.layers[:-1])
model_B_on_A.add(keras.layers.Dense(1, activation="sigmoid"))- model_A와 model_B_on_A는 일부 층을 공유
- model_B_on_A를 훈련할 때 model_A도 영향을 받음 이를 막기 위해서는 재사용 전에 model_A를 clone하고 사용
- clone_model() 메서드로 모델 A의 구조를 복제한 후 가중치를 복사
model_A_clone = keras.models.clone_model(model_A)
model_A_clone.set_weights(model_A.get_weights())
model_B_on_A = keras.models.Sequential(model_A_clone.layers[:-1])
model_B_on_A.add(keras.layers.Dense(1, activation="sigmoid"))- 새로운 출력층이 랜덤 초기화 되어 있기 때문에 초반에 큰 오차를 생성
- 따라서 큰 오차가 그레이디언트가 재사용된 가중치를 망칠 가능성이 존재
- 이를 피하기 위해서 처음 몇 번의 에포크 동안 재사용 된 층을 동결하고 새로운 층에게 적절한 가중치를 학습할 시간을 주는 것이 좋음
for layer in model_B_on_A.layers[:-1]:
layer.trainable = False
model_B_on_A.compile(loss="binary_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=1e-3),
metrics=["accuracy"])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=4,
validation_data=(X_valid_B, y_valid_B))
for layer in model_B_on_A.layers[:-1]:
layer.trainable = True
model_B_on_A.compile(loss="binary_crossentropy",
optimizer=keras.optimizers.SGD(learning_rate=1e-3),
metrics=["accuracy"])
history = model_B_on_A.fit(X_train_B, y_train_B, epochs=16,
validation_data=(X_valid_B, y_valid_B))- 몇번의 epoch 동안 출력층을 동결하고 이후 다시 활성화 하여 모델 학습
- 전이학습은 심층 신경망에서 더 잘 작동 완전 연결층 보다
비지도 사전훈련
- 레이블된 훈련 데이터가 많지 않은 복잡한 문제가 있을때 비슷한 훈련을 한 모델이 없는 경우
- 먼저 더 많은 레이블된 훈련데이터를 수집후 비지도 사전학습을 수행
- 오토인코더나 적대적 생성 신경망과 같은 비지도 학습 모델을 훈련할 수 있음
- 그다음 오토인코더나 gan 판별자의 하위층을 재사용하고 그 위에 새로운 작업에 맞는 출력층을 추가할 수 있음
보조 작업에서 사전훈련
레이블된 훈련 데이터가 많지 않다면 마지막 선택 사항은 레이블된 훈련 데이터를 쉽게 얻거나 생성할 수 있는 보조 작업에서 첫 번째 신경망을 훈련하는 것
신경망의 하위층을 실제 작업을 위해 재사용, 첫 번째 신경망의 하위층은 두 번째 신경망에 재사용될 수 있는 특성 추출기를 학습하게 됨
자기 지도 학습 : 데이터에서 스스로 레이블을 생성하고 지도 학습 기법으로 레이블된 데이터셋에서 모델을 훈련하는 방법
고속 옵티마이저
- 아주 큰 신경망의 훈련 속도는 심각하게 느릴 수 있음
- 연결 가중치에 좋은 초기화 전략 사용하기, 좋은 활성화 함수 사용하기, 배치 정규화 사용하기, 사전훈련된 네트워크의 일부 재사용하기등 존재
- 훈련 속도를 크게 높일수 있는 또 다른 방법으로 표준적인 경사 하강법 옵티마이저 대신 더 빠른 옵티마이저를 사용할 수 있음
- 모멘텀 최적화, 네스테로프 가속 경사, AdaFrad, RMSProp, Adam, Nadam
모멘텀 최적화
처음에는 느리게 출발하지만 종단속도에 도달할 때까지는 빠르게 가속
- 반대로 표준적인 경사 하강법은 경사면을 따라 일정한 크기의 스텝으로 조금씩 천천히 내려감
- 그래서 맨 아래에 도착하는 데 시간이 더 오래 걸림
경사 하강법은 가중치에 대한 비용함수




공식은

- 해당 공식은 이전 그레이디언트가 얼마인지는 고려하지 않음
- 해당 공식은 국부적으로 그레이디언트가 아주 작으면 매우 느려짐
모멘텀 최적화는 이전 그레이디언트가 얼마였는지를 상당히 중요하게 생각
매 반복에서 현재 그레이디언트를 모멘텀 벡터 m에 더하고 이 값을 빼는 방식으로 가중치를 갱신
- 그레이디언트를 속도가 아니라 가속도로 사용
- 일종의 마찰저항을 표현하고 모멘텀이 너무 커지는 것을 막기 위해 이 알고리즘에는 모멘텀이라는 새로운 파라미터 등장 (


- 공식
그레이디언트가 일정하다면 종단속도는 학습률



- 이를 통해서 모멘텀 최적화가 경사 하강법보다 더 빠르게 평편한 지역을 탈출하게 도와줌
- 경사 하강법이 가파른 경사를 꽤 빠르게 내려가지만 좁고 긴 골짜기에서는 오랜 시간이 걸림
- 반면에 모멘텀 최적화는 골짜기를 따라 최적점에 도달할때 까지 점점 더 빠르게 내려감
- 모멘텀 최적화를 사용하면 지역 최적점을 건너뛰는데 도움을 줌
kears 모멘텀 최적화 구현하는 방법
optimizer = keras.optimizers.SGD(learning_rate=0.001, momentum=0.9)


네스테로프 가속 경사 (NAG)
기본 모멘텀 최적화보다 거의 항상 더 빠름
현재 위치가


- 네스테로프 가속 경사 알고리즘
- 네스테로프 가속 경사 알고리즘
일반적으로 모멘텀 벡터가 올바른 방향을 가리킬 것이므로 이런 변경이 가능
원래 위치에서 그레이디언트를 사용하는 것 대신에 그 방향으로 조금 더 나아가서 측정한 그레이디언트를 사용
NAG가 최적값에 조금 더 가까운 경향이 있고 시간이 지나면서 작은 개선이 반영되어 기본 모멘텀 최적화보다 확연히 빨라지게 됨
일반적으로 NAG가 기본 모멘텀 최적화보다 훈련 속도가 빠름, SGD에 use_nesterov=True로 사용
optimizer = keras.optimizers.SGD(learning_rate=0.001, momentum=0.9, nesterov=True)


AdaGrad
경사 하강법은 전역 최적점 방향으로 곧장 향하지 않고 가장 가파른 경사를 따라 빠르게 내려가기 시작해 골짜기 아래로 느리게 이동
- 알고리즘이 이를 일찍 감지하고 전역 최적점 쪽으로 좀 더 정확한 방향을 잡으면 더 좋음
- AdaGrad 알고리즘은 가장 가파른 차원을 따라 그레이디언트 벡터의 스케일을 감소시켜 문제를 해결
AdaGrad 알고리즘


- (/) 는 원소별 나눗셈
AdaGrad는 학습률을 감소시키지만 경사가 완만한 차원보다 가파른 차원에 대해 더 빠르게 감소됨, 이를 적응적 학습률이라고 부르며, 전역 최적점 방향으로 더 곧장 가도록 갱신되는데 도움을 줌
학습률 하이퍼파라미터

단점
- AdaGrad는 2차방정식 문제에서는 잘 작동하지만 신경망을 훈련할 때 너무 일찍 종료되는 문제가 존재
- 이 때문에 심층 신경망에서는 사용하면 안됨
- 대신 선형 회귀와 같은 간단한 작업에는 효과적일수 있음
- AdaGrad는 2차방정식 문제에서는 잘 작동하지만 신경망을 훈련할 때 너무 일찍 종료되는 문제가 존재
RMSProp
- AdaGrad는 너무 빨리 느려져서 전역 최적점에 수렴하지 못하는 위험이 존재
- RMSProp 알고리즘은 가장 최근 반복에서 비롯된 그레이디언트만 누적함으로써 해당 문제를 해결
- 알고리즘의 첫 번째 단계에서 지수 감소를 사용
- RMSProp 알고리즘


optimizer = keras.optimizers.RMSprop(learning_rate=0.001, rho=0.9)- 일반적으로 AdaGrad보다 훨씬 성능이 좋음
- Adam 최적화가 나오기 전까지 가장 선호되던 알고리즘
Adam과 Nadam 최적화
적응적 모멘트 추정을 의미하는 Adam은 모멘텀 최적화와 RMSProp의 아이디어를 합친것
지난 그레이디언트의 지수 감소 평균을 따르고 RMSProp처럼 지난 그레이디언트 제곱의 지수 감소된 평균을 따름
Adam 알고리즘
모멘텀 감쇠 하이퍼파라미터


kears에서 Adam 옵티마저 예제
optimizer = keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999)Adam은 적은적 학습률 알고리즘이기 때문에 학습률 하이퍼파라미터








- Adam의 두가지 변종
- AdaMax
- 시간에 따라 감쇠된 그레이디언트의 최댓값
- 실전에서 AdaMax가 Adam보다 안정적이지만 데이터셋에 따라 다르고 일반적으로 Adam이 좋음
- Adam이 잘 작동되지 않는다면 AdaMax 추천
- Nadam
- Adam에 NAG 기법을 합친것
- 종종 Adam보다 빠르게 수렴
- 일반적으로 Nadam이 Adam보다 좋았지만 RMSProp가 좋을 때도 존재
- AdaMax
- 소개된 모든 옵티마이저 비교


학습률 스케줄링
컴퓨팅 자원이 한정적이라면 차선의 솔류션을 만들기 위해 완전히 수렴하기 전에 훈련을 멈춰야함
일정한 학습률로 수백 번 반복하여 좋은 학습률을 찾을수 있지만 일정한 학습률 보다 더 좋은 방법이 존재
큰 학습률로 시작하고 학습 속도가 느려질 때 학습률을 낮추면 최적의 고정 학습률보다 좋은 솔류션을 더 빨리 발견할 수 있음
훈련하는 동안 학습률을 감소기키는 전략에는 여러 가지가 존재, 이런 전략을 학습 스케줄이라고 함
거듭제곱 기반 스케줄링
학습률을 반복 횟수 t에 대한 함수


optimizer = keras.optimizers.SGD(learning_rate=0.01, decay=1e-4)
지수 기반 스케줄링
학습률을

def exponential_decay_fn(epoch): return 0.01 * 0.1**(epoch / 20)
구간별 고정 스케줄링
일정 횟수의 에포크 동안 일정한 학습률을 사용하고, 그다음 또 다른 횟수의 에포크 동안 작은 학습률을 사용하는 방식
def piecewise_constant_fn(epoch): if epoch < 5: return 0.01 elif epoch < 15: return 0.005 else: return 0.001
성능 기반 스케줄링
매 N 스텝마다 검증 오차를 측정하고 오차가 줄어들지 않을 경우 λ배만큼 학습률을 감소시킨다.
lr_scheduler = keras.callbacks.ReduceLROnPlateau(factor=0.5, patience=5)
1사이클 스케줄링
- 훈련 절반 동안 초기 학습률





- 훈련 절반 동안 초기 학습률
규제를 사용해 과대적합 피하기
- 심층 신경망은 전형적으로 수만 개, 때로는 수백만 개의 파라미터를 가지고 있음
- 이 때문에 네트워크의 자유도가 매우 높음
- 대규모의 복잡한 데이터셋을 학습할 수 있다는 뜻
- 하지만 이런 높은 자유도는 네트워크를 훈련 세트에 과대적합되기 쉽게 만듬
- 규제가 필요
- 신경망에서 널리 사용되는 다른 규제 방법을 소개

L1, L2 규제
간단한 선형 모델에 했던 것처럼 신경망의 연결 가중치를 제한하기 위해 L2 규제를 사용하거나 희소 모델을 만들기 위해 L1 규제를 사용할 수 있음
keras 층의 연결 가중치에 규제 강도 0.01을 사용하여 L2 규제를 적용하는 방법 예시
layer = keras.layers.Dense(100, activation="elu", kernel_initializer="he_normal", kernel_regularizer=keras.regularizers.l2(0.01))- L2 함수는 훈련하는 동안 규제 손실을 계산하기 위해 각 스텝에서 호출되는 규제 객체를 반환
- L1 규제는 keras.regularizers.l1 사용, 둘다는 keras.regularizers.l1_l2 사용
일반적으로 네트워크의 모든 은닉층에 동일한 활성화 함수, 동일한 초기화 전략을 사용하거나 모든 층에 동일한 규제를 적용하기 때문에 매개변수 값을 반복하는 경우가 많음
python의 functools.partial() 함수를 사용하여 기본 매개변수 값을 사용하여 함수 호출을 감싸는 방법
- 동일한 매개변수 값을 사용하는 경우 버그 방지를 위한 방법
from functools import partial RegularizedDense = partial(keras.layers.Dense, activation="elu", kernel_initializer="he_normal", kernel_regularizer=keras.regularizers.l2(0.01)) model = keras.models.Sequential([ keras.layers.Flatten(input_shape=[28, 28]), RegularizedDense(300), RegularizedDense(100), RegularizedDense(10, activation="softmax") ]) model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam", metrics=["accuracy"]) n_epochs = 2 history = model.fit(X_train_scaled, y_train, epochs=n_epochs, validation_data=(X_valid_scaled, y_valid))
드롭아웃
심층 신경망에서 가장 인기 있는 규제 기법
매 훈련 스탭에서 각 뉴런은 임시적으로 드롭아웃될 확률 p를 가짐
- 즉 이번 훈련 스탭에는 완전히 무시되지만 다음 스탭에는 활성화될 수 있음
- 하이퍼파라미터 p를 드롭아웃 비율이라고 하고 보통 10%dhk 50% 사이를 지정
- 순환 신경망에서는 20%
30%에 가깝고 합성곱 신경망에서는 40%50%에 가까움
훈련이 끝난 후에는 뉴런에 더는 드롭아웃을 적용하지 않음
일반적으로 출력층을 제외한 맨 위의 층부터 세 번째 층까지 있는 뉴런에만 드롭아웃을 적용
훈련이 끝난 뒤 각 입력의 연결 가중치에 보존 확률 (1-p)를 곱해야 함
keras 드롭아웃 예제
model = keras.models.Sequential([ keras.layers.Flatten(input_shape=[28, 28]), keras.layers.Dropout(rate=0.2), keras.layers.Dense(300, activation="elu", kernel_initializer="he_normal"), keras.layers.Dropout(rate=0.2), keras.layers.Dense(100, activation="elu", kernel_initializer="he_normal"), keras.layers.Dropout(rate=0.2), keras.layers.Dense(10, activation="softmax") ]) model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam", metrics=["accuracy"]) n_epochs = 2 history = model.fit(X_train_scaled, y_train, epochs=n_epochs, validation_data=(X_valid_scaled, y_valid))모델이 과대적합 되었다면 드롭아웃 비율을 늘릴수 있음
- 반대로 과소적합이라면 비율 낮춰야함
드롭아웃은 수렴을 느리게 하지만 적절하게 튜닝하면 훨씬 더 좋은 모델을 생성
SELU 활성화 함수와 같이 사용하려면 alpha 드롭아웃을 사용해야함
model = keras.models.Sequential([ keras.layers.Flatten(input_shape=[28, 28]), keras.layers.AlphaDropout(rate=0.2), keras.layers.Dense(300, activation="selu", kernel_initializer="lecun_normal"), keras.layers.AlphaDropout(rate=0.2), keras.layers.Dense(100, activation="selu", kernel_initializer="lecun_normal"), keras.layers.AlphaDropout(rate=0.2), keras.layers.Dense(10, activation="softmax") ]) optimizer = keras.optimizers.SGD(learning_rate=0.01, momentum=0.9, nesterov=True) model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"]) n_epochs = 20 history = model.fit(X_train_scaled, y_train, epochs=n_epochs, validation_data=(X_valid_scaled, y_valid))
몬테 카를로 드롭아웃
드롭아웃을 수학적으로 정의하여 드롭아웃 네트워크와 근사 베이즈 추론 사이에 깊은 관련성을 정립
저자들은 훈련된 드롭아웃 모델을 재 훈련하거나 전혀 수정하지 않고 성능을 크게 향상시킬 수 있는 몬테 카를로 드롭아웃이라 불리는 강력한 기법을 소개함
모델의 불확실성을 더 잘 측정할 수 있고 구현도 쉬움
앞서 훈련한 드롭아웃 모델을 재훈련 하지않고 성능을 향상시키는 MC 드롭아웃 구현
y_probas = np.stack([model(X_test_scaled, training=True) for sample in range(100)]) y_proba = y_probas.mean(axis=0) y_std = y_probas.std(axis=0)training=True로 지정하여 Dropout 층을 활성화하고 테스트 세트에서 100번의 예측을 만들어 쌓음
드롭아웃이 활성화 되었기 때문에 예측이 변경됨 y_probas는 [100, 10000, 10] 크기의 행렬
- 첫 번째 차원 (axis=0)을 기준으로 평균하면 한 번의 예측을 수행했을 때와 같은 [10000, 10] 크기의 배열 y_broba를 얻게 됨
예제
class MCDropout(keras.layers.Dropout): def call(self, inputs): return super().call(inputs, training=True) class MCAlphaDropout(keras.layers.AlphaDropout): def call(self, inputs): return super().call(inputs, training=True) mc_model = keras.models.Sequential([ MCAlphaDropout(layer.rate) if isinstance(layer, keras.layers.AlphaDropout) else layer for layer in model.layers ]) optimizer = keras.optimizers.SGD(learning_rate=0.01, momentum=0.9, nesterov=True) mc_model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"]) mc_model.set_weights(model.get_weights()) np.round(np.mean([mc_model.predict(X_test_scaled[:1]) for sample in range(100)], axis=0), 2)
멕스-노름 규제
신경망에서 널리 사용되는 또 다른 규제 기법은 맥스-노름 규제
- 각각의 뉴런에 대해 입력의 연결 가중치 w 가

- r은 맥스-노름 하이퍼파라미터고

- r은 맥스-노름 하이퍼파라미터고
- 각각의 뉴런에 대해 입력의 연결 가중치 w 가
맥스-노름 규제는 전체 손실 함수에 규제 손실 항을 추가하지 않음, 대신 일반적으로 매 훈련 스탭이 끝나고

r을 줄이면 규제의 양이 증가하여 과대적합을 감소시키는데 도움을 줌
맥스-노름 규제는 불안정한 그레이디언트 문제를 완화하는데 도움을 줌
keras에서의 맥스-노름 규제
layer = keras.layers.Dense(100, activation="selu", kernel_initializer="lecun_normal", kernel_constraint=keras.constraints.max_norm(1.))- max_norm 함수는 기본값이 0인 axis 매개변수 존재
- Dense 층은 일반적으로 [샘플개수, 뉴런 개수] 크기의 가중치를 가짐
- axis=0 사용하면 맥스-노름 규제는 각 뉴런의 가중치 벡터에 독립적으로 적용
- 일반적으로 합성곱에서는 axis=[0,1,2]
요약 및 실용적인 가이드라인
기본 DNN 설정

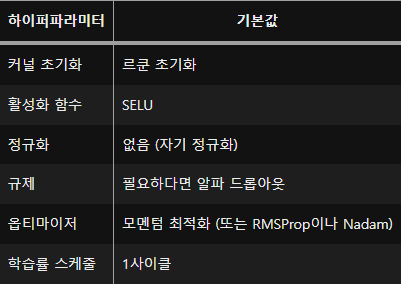
자기 정규화를 위한 DNN 설정
'Study > Self Education' 카테고리의 다른 글
| 핸즈온 머신러닝 - 13 (0) | 2024.06.19 |
|---|---|
| 핸즈온 머신러닝 - 12 (0) | 2024.06.19 |
| 핸즈온 머신러닝 - 10 (0) | 2024.06.19 |
| 핸즈온 머신러닝 - 9 (0) | 2024.06.18 |
| 핸즈온 머신러닝 - 8 (0) | 2024.06.18 |