
[Space-S x DLD 2022] 케라스 실용 예제 및 개발 가이드 컨퍼런스 - Advanced Augmentation Strategy in Keras 리뷰
|2024. 7. 22. 17:36
반응형
- 강의 링크
- 강의 자료
- AIF Seminar
- AIFactory 에서 제공하는 '[Space-S x DLD 2022] 케라스 실용 예제 및 개발 가이드 컨퍼런스' 세미나 후기입니다.
Advanced Augmentation Strategy in Keras
Data Augmentation이란?
- 학습/추론에 사용하는 데이터의 양을 늘리기 위해 적용
- Data space에서 비어 있는 공간을 채워 generalization 효과 증가 (overfitting 해결)
- Image와 Text 등 다양한 도메인의 특징에 맞게 적용
- Augmentation의 종류(Image)
- Pixel-level
- Spatial-level
- Generative model
- Advanced augmentation strategy
Basic Image Manipulation
- Pixel-level Transforms
- pixel 단위로 변환을 적용하는 기법으로 color, blur, noise등을 변화시키거나 추가
- 변환 정도를 수치적으로 지정하여 사용

- Spatial-level Transforms
- Flip, Rotation, Crop 등 Image의 위상을 변경
- Cutout: Image의 일부를 잘라내는 변환 기법

- Generative model Based Approach
- 생성 모델을 활용하여 학습에 사용할 데이터를 생성하는 기법
- 주로 데이터의 수가 매우 적거나 data noise가 많을 때 사용
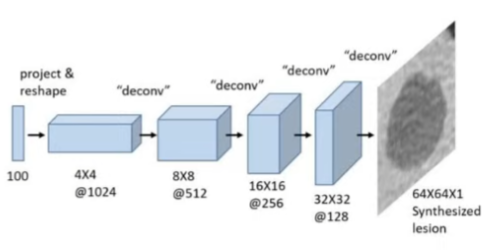
Data Augmentation 사용 시 주의사항
- Data Augmentation은 의미가 변형되지 않는 선에서 적용
- Domain에 따라 적용 가능한 data augmentation의 범위가 달라짐
- 학습하는 데이터가 수집된 domain konwledge를 통해 더 좋은 data augmentation pool 구성 가능

어떤 특징을 가지고 있는지 파악!, 데이터가 수집된 knowledge를 가져야함
Test Time Augmentation(TTA)
- 추론 과정에서 성능 향상을 위해 사용하는 기법
- class를 예측해서 voting
- 추론할 이미지 여러개 만들어둬야함
Advanced Augmentation Strategy
- 여러 이미지를 섞어 완전히 새로운 데이터를 생성하는 기법
- Cutmix, Mixup을 시작으로 puzzle mix등 다양한 알고리즘 연구중
- RandAugment : 강화학습 기반으로 가장 효율적인 Data augmentation 알고리즘 search
- 여러 data augmentation pool에서 선택적으로 dataset에 맞게 적용
Code Review
import keras_cv
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow import keras
from tensorflow.keras import applications
from tensorflow.keras import losses
from tensorflow.keras import optimizers- Flower Dataset을 사용한 분류 문제 데이터
BATCH_SIZE = 32 # 배치 사이즈
AUTOTUNE = tf.data.AUTOTUNE
tfds.disable_progress_bar()
data, dataset_info = tfds.load("oxford_flowers102", with_info=True, as_supervised=True)
# tarin, val split
train_steps_per_epoch = dataset_info.splits["train"].num_examples // BATCH_SIZE
val_steps_per_epoch = dataset_info.splits["test"].num_examples // BATCH_SIZE- 이미지 해상도는 224, 224
IMAGE_SIZE = (224, 224)
num_classes = dataset_info.features["label"].num_classes
def to_dict(image, label):
image = tf.image.resize(image, IMAGE_SIZE)
image = tf.cast(image, tf.float32)
label = tf.one_hot(label, num_classes)
return {"images": image, "labels": label}
# train, test에 사용할 데이터셋 구분
def prepare_dataset(dataset, split):
if split == "train":
return (
dataset.shuffle(10 * BATCH_SIZE)
.map(to_dict, num_parallel_calls=AUTOTUNE)
.batch(BATCH_SIZE)
)
if split == "test":
return dataset.map(to_dict, num_parallel_calls=AUTOTUNE).batch(BATCH_SIZE)
def load_dataset(split="train"):
dataset = data[split]
return prepare_dataset(dataset, split)
train_dataset = load_dataset()- Dataset 시각화
- Augmentation 적용 이전
- 실제 학습에 사용되는 데이터 이미지 확인
def visualize_dataset(dataset, title):
plt.figure(figsize=(6, 6)).suptitle(title, fontsize=18)
for i, samples in enumerate(iter(dataset.take(9))):
images = samples["images"]
plt.subplot(3, 3, i + 1)
plt.imshow(images[0].numpy().astype("uint8"))
plt.axis("off")
plt.show()
visualize_dataset(train_dataset, title="Before Augmentation")- RandAugment
- 강화학습 기반으로 최적의 Augmentation 찾아줌
-
# 값을 정하는 기준은 없음, 해보면서 판단 - 'value_range'는 이미지에 포함된 값의 범위 - 'magnitude'는 augmentation 강도를 나타내는 0과 1 사이의 값 - 'augmentations_per_image'는 레이어에 각각에 적용할 증강의 수를 알려주는 정수 - (선택 사항) 'magnitude_stddev'는 'magnitude'가 무작위로 샘플링되도록 하는 수 - (선택사항) 'rate'는 증강을 적용할 확률
rand_augment = keras_cv.layers.RandAugment(
value_range=(0, 255),
augmentations_per_image=3,
magnitude=0.3,
magnitude_stddev=0.2,
rate=0.5,
)
def apply_rand_augment(inputs):
inputs["images"] = rand_augment(inputs["images"])
return inputs
train_dataset = load_dataset().map(apply_rand_augment, num_parallel_calls=AUTOTUNE)
visualize_dataset(train_dataset, title="After RandAugment")
- Cutmix, Mixup
- class 여러개가 섞임
- 실제로 존재하지 않는 데이터를 학습하면서 모델이 robust 해짐
cut_mix = keras_cv.layers.CutMix()
mix_up = keras_cv.layers.MixUp()
def cut_mix_and_mix_up(samples):
samples = cut_mix(samples, training=True)
samples = mix_up(samples, training=True)
return samples
train_dataset = load_dataset().map(cut_mix_and_mix_up, num_parallel_calls=AUTOTUNE)
visualize_dataset(train_dataset, title="After CutMix and MixUp")
- Customize augmentation
- GridMask() : 이미지 일부분을 사각형이나, 마름모로 마스킹 추가
- 흑백이미지도 학습에 사용
pipeline = keras_cv.layers.RandomAugmentationPipeline(
layers=[keras_cv.layers.GridMask(), keras_cv.layers.Grayscale(output_channels=3)],
augmentations_per_image=1,
)
train_dataset = load_dataset().map(apply_pipeline, num_parallel_calls=AUTOTUNE)
visualize_dataset(train_dataset, title="After custom pipeline")
- Training a CNN
- label도 변화됨 -> cutmix, mixup keras함수는 자동 지정
def preprocess_for_model(inputs):
images, labels = inputs["images"], inputs["labels"]
images = tf.cast(images, tf.float32)
return images, labels
train_dataset = (
load_dataset()
.map(apply_rand_augment, num_parallel_calls=AUTOTUNE)
.map(cut_mix_and_mix_up, num_parallel_calls=AUTOTUNE)
)
visualize_dataset(train_dataset, "CutMix, MixUp and RandAugment")
train_dataset = train_dataset.map(preprocess_for_model, num_parallel_calls=AUTOTUNE)
test_dataset = load_dataset(split="test")
test_dataset = test_dataset.map(preprocess_for_model, num_parallel_calls=AUTOTUNE)
train_dataset = train_dataset.prefetch(AUTOTUNE)
test_dataset = test_dataset.prefetch(AUTOTUNE)
train_dataset = train_dataset
test_dataset = test_dataset
- 모델은 DenseNet121 사용
- label_smoothing : class 들 사이에서 바운더리를 10%확률로 나눠가지게 하는 기법
input_shape = IMAGE_SIZE + (3,)
def get_model():
model = keras_cv.models.DenseNet121(
include_rescaling=True, include_top=True, classes=num_classes
)
model.compile(
loss=losses.CategoricalCrossentropy(label_smoothing=0.1),
optimizer=optimizers.SGD(momentum=0.9),
metrics=["accuracy"],
)
return model
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = get_model()
model.fit(
train_dataset,
epochs=1,
validation_data=test_dataset,
)
최신 연구 동향
- class 마다 data augmentation의 효과가 다르게 적용
- 일부 class 정확도 희생에 전체의 정확도 상승
-> 각 class 마다 적절한 augmentation을 적용하기 위한 연구
일부를 희생해서 전체의 성능을 올림, 즉 class 마다 서로 다른 augmentation을 적용해야 된다.
강의 후기
- Data Augmentation에 대해서 크게 생각하지 않았는데 이번 강의를 통해 Augmentation 기법이 강력하다는 것을 알 수 있었습니다.
- 이후 프로젝트나 개인적인 분류 모델 작성 시 사용해봐야 하겠습니다.
- 일부 class에 따라 augmentation을 다르게 지정하는것이 좋다는 것은 신기했습니다.
반응형
'Study > Seminar' 카테고리의 다른 글
| [AIF] 개인 데이터셋을 통한 llama2 fine-tune (4) | 2024.07.22 |
|---|---|
| [AIF] 챗GPT 점메추 메뉴판, 예산입력하고 점심 메뉴 추천받자 (17) | 2024.07.22 |
| [AIFLD2023] 어쩌다 키포인트 검출 제대로 입문하기 (2) | 2024.07.22 |
| INNOPOLIS AI SPACE-S 인공지능 세미나 - 이미지 분류를 위한 딥러닝 문제해결 패턴 리뷰 (1) | 2024.07.22 |
| INNOPOLIS AI SPACE-S 인공지능 세미나 - 정형 데이터를 다루는 머신러닝 문제해결 패턴 리뷰 (2) | 2024.07.22 |