
반응형
- 논문 링크 : Fast R-CNN
Introduction
- 기존의 Object detection 모델은 객체 위치까지 찾아야 하는 작업이 추가되어 multi-stage 파이프라인으로 구성되었음
- multi-stage 파이프라인 때문에 속도 느리고 복잡함
- multi-stage는 이미지분류, 객체 위치 찾는 과정을 각각 다른 파이프라인에서 수행
- R-CNN은 conv 훈련, SVM 분류, bounding box regression 3단계가 각각의 파이프라인에서 수행되는 multi-stage
Fast R-CNN에서는 객체를 분류하는일, 후보 영역에서 정확한 위치를 탐색하는일을 동시에 수행하는 single-stage 제안
- Fast R-CNN 장점
- 훈련과 테스트 단계에서 빠른 속도를 보여줌 (R-CNN 보다)
- 훈련이 single-stage임 , R-CNN의 loss인 multi-task loss를 사용하지만 multi-stage 모델이 아님
- 훈련을 하면서 network 전체 파라미터 업데이트 수행
- 피처 캐싱을 위한 저장 공간이 별도로 필요하지 않음
Fast R-CNN 핵심
- RoI Pooling
- Initializing from pre-trained networks
- Fine-tuning for detection
- Truncated SVD
- RoI Pooling
- R-CNN에서 CNN output이 FC layer의 input으로 들어가야 했기 때문에 CNN input을 고정시켜 일정한 size로 변경하는 과정이 있었음
- 실제로 FC layer의 input이 고정이고 CNN input은 고정이 아니기때문에 FC layer의 input에 들어갈때만 size를 맞춰주면 됨
- 이 과정에서 Spatial Pyramid Pooling(SPP) 제안됨
- Spatial Pyramid Pooling(SPP)

- 이미지를 CNN 통과 시켜 feature map 추출
- 사전에 정의된 4x4, 2x2, 1x1 영역의 피라미드로 feature map 나눠줌, feature map 한칸을 bin
- bin 내에서 max pooling 적용해서 각 bin마다 하나의 값 추출
- 맨 왼쪽 1x1로 분할후 각각의 cell마다 maxpooling 수행해서 길이가 1인 vector 16x256 얻음
- 가운대 2x2로 분할후 각각의 cell마다 maxpooling 수행해서 길이가 4인 vector 4x256
- 오른쪽 4x4로 분할수 각각의 cell마다 maxpooling 수행해서 길이 16 vector 16*256 얻음
- 최종적으로 피라미드 크기만큼 max값을 추출해서 3개의 피라미드 결과를 붙인 고정된 크기 vector 생성
- —> 얻어진 vector 연결해서 21*256 vector 얻음
- 결과 적으로 feature map을 고정된 분할(1x1,2x2,4x4)로 나눈 후 각 분할에 대해 pooling을 진행한다. 따라서 feature map의 크기가 달라도 고정된 길이의 vector를 얻음

- —> R-CNN에서는 2000개의 후보영역에 대해서 각각 CNN 연산을 수행했는데 Fast R-CNN에서는 1번의 CNN연산으로 줄어듦
- 위 그림과 같이 1개의 피라미드를 적용시킨 SPP로 구성
- 피라미드 사이즈 7x7 (SPP단계에서 4x4,2x2,1x1)
- 나온 각각의 feature 붙여서 고정된 크기의 feature vector 얻는 과정이 RoI Pooling
- RoI Pooling
- Fast R-CNN에서 input 이미지 CNN 통과시켜 알록달록한 위의 사각형의 feature map 추출 (feature map은 알록달록한 상자 검은선X)
- Selective search로 얻은 RoI를 feature map에 투영 (위의 feature map에 검은색 박스가 겹쳐짐)
- (R-CNN 논문 리뷰의 selective search 참조)
- Fast R-CNN에서 얻어야하는 고정된 크기는 H x W
- RoI는 r,c,h,w 값을 가지고 (r,c) = 최상단 좌표값 , (h,w) = 높이와 너비
- 이를 통해서 윈도우 크기는 (h/H * w/W) 가 됨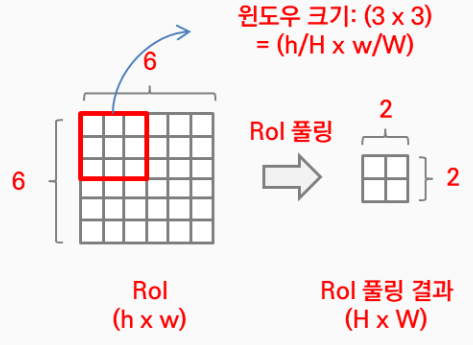
- 위의 과정을 통해서 feature map 이전의 RoI를 투영시켜 FC layer의 고정된 크기에 맞게 변형
- RoI Pooling은 쉽게 표현하면 크기가 다른 feature map의 region마다 stride를 다르게 적용한 max pooling을 진행해서 결과값을 동일하게 만드는것
ex) 7x7 output 만들기위해 각각의 region이 21x14 , 42x35 영역이 있다면
- 21x14 영역에는 stride (3,2) 21/3 * 14/2 ⇒ 7*7
- 42x35 영역에는 stride (6,5) 42/6 * 35/5 ⇒ 7*7
- 이렇게 고정된 7*7 size 만드는것- Initializing from pre-trained networks
- R-CNN은 ImageNet 으로 pre-train AlexNet을 이용
- Fast R-CNN은 ImageNet 으로 pre-train VGG16을 이용
- 3가지 변형을 줌
- CNN에서 마지막 pooling layer를 RoI pooling layer으로 변경 (FC layer 입력으로 H*W 크기를 받을수 있게 , 논문에서 H=W=7)
- 마지막 FC layer을 (FC latey + softmax), bounding-box regressor 층으로 변경
- softmax layer의 output 개수를 K+1(category의 개수 + 배경)로 바꾸고, category별 bounding-box regressor를 추가
- input으로 images와 해당 images의 RoIs를 입력받을 수 있게 변형 (input 2개)
- 3가지 변형을 줌
- VGG 특징
- 특징
- conv 사이즈 3x3으로 고정
- 연산하여 발생하는 파라미터 개수가 줄어드는 효과와 ReLU 활성화 함수를 적용시킬수 있을만큼 깊은 신경망 가능
- ReLU는 음수는 0 , 나머지 값은 입력값 그대로 나오는 함수
- ReLU의 비선형성을 가지게 하면서 레이어가 깊어질수록 학습 효과가 증폭
- 기존의 큰 필터의 conv는 빨리 이미지가 줄어들어서 깊은 신경망 만들기에는 적합하지 않음

- 왼쪽(7x7 conv) 파라미터는 49개 생성
- 오른쪽(3x3 conv) 파라미터 27개 생성
- 5x5 필터와 동일한 효과에 파라미터도 더 적음
- VGG 이러한 특성때문에 3x3, stride=1
- VGG와 Fast R-CNN network
- VGG-16 구성
| conv 3x3 |
| --- |
| conv 3x3 |
| max pooling |
| conv 3x3 |
| conv 3x3 |
| max pooling |
| conv 3x3 |
| conv 3x3 |
| conv 3x3 |
| max pooling |
| conv 3x3 |
| conv 3x3 |
| conv 3x3 |
| max pooling |
| conv 3x3 |
| conv 3x3 |
| conv 3x3 |
| max pooling |
| Dense |
| Dense |
| Dense(softmax) |
- Fast R-CNN 구성
| conv 3x3 |
| --- |
| conv 3x3 |
| max pooling |
| conv 3x3 |
| conv 3x3 |
| max pooling |
| conv 3x3 |
| conv 3x3 |
| conv 3x3 |
| max pooling |
| conv 3x3 |
| conv 3x3 |
| conv 3x3 |
| max pooling |
| conv 3x3 |
| conv 3x3 |
| conv 3x3 |
| max pooling |
| RoI Pooling layer |
|(input : image feature + RoI) |
| Dense |
| Dense |
| 1. Dense(softmax)<br />2. bounding box regressor |- Fine-tuning for detection
- Fast R-CNN은 역전파를 통해 네트워크 모든 가중치를 학습
- 역전파(back-propagation) : target 값과 실제 모델이 계산한 output이 얼마나 차이가 나는지 구한 후 그 오차값을 다시 뒤로 전파해가면서 각 노드가 가지고 있는 변수들을 갱신하는 알고리즘
- 효율적인 학습을 위해 Fast R-CNN에서 hierarchical sampling
을 사용, 이러한 sampling 방법이외에 Multi-task loss
를 이용해 softmax classifier와 bounding-box regressors를 한번의 fine-tuning으로 학습- Hierarchical sampling
- Fast R-CNN 학습시에는, SGD mini-batches는 계층적으로 샘플링
- Hierarchical sampling을 통해 SGD mini-batch를 구성하는 방법
- N = image 개수, R = RoI 개수
- N개의 image를 sampling 한 후, 각각의 image에서 R/N개의 RoIs를 sampling
- 같은 image에서 온 RoIs는 순전파와 역전파시 연산과 memory를 공유
- 순전파 : 입력층에서 은닉층 방향으로 이동하면서 각 입력에 해당하는 가중치가 곱해지고, 결과적으로 가중치 합으로 계산되어 은닉층 뉴런의 함수 값
- N을 작게하면 mini-batch 연산을 줄임
- 논문에서 적용
- 논문에서 N=2, R=128로 설정
- 논문의 예시에서는 64개의 RoI를 각 image에서 sampling
- 총 64개의 RoI 중에서 25%(16개)은 ground truth와 IoU(Intersection of Union)값이 0.5 이상인 sample에서 추출
- 나머지 75%(48개)는 IoU값이 0.1~0.5 사이의 sample에서 추출한다.
- 전자의 경우는 positive sample(객체), 후자는 negative sample(배경)
- Multi-task loss
- softmax classifier, bounding-box regressors을 한번에 학습하기 위해 multi-task loss를 사용
- 공식
- parameter 설명
 : K+1개의 class score
: K+1개의 class score : class ground truth
: class ground truth : u 클래스의 bounding box 좌료를 조정하는 값
: u 클래스의 bounding box 좌료를 조정하는 값- (R-CNN에서 regressor output처럼 해당 좌표가 아니라 ground truth 좌표를 계산할 수 있게 해주는 값)
 : bounding box 좌표값의 ground truth
: bounding box 좌표값의 ground truth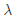 : hyperparameter(논문에서 λ=1)
: hyperparameter(논문에서 λ=1)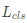 는 cross-entropy error로 계산
는 cross-entropy error로 계산
- cross-entropy error : 머신 러닝의 분류 모델이 얼마나 잘 수행되는지 측정하기 위해 사용되는 지표입니다. Loss 0은 완벽한 모델로 0과 1 사이의 숫자로 측정됩니다. 일반적인 목표는 모델을 가능한 0에 가깝게 만드는 것
 는 다음과 같이 정의됨
는 다음과 같이 정의됨
- [u≥1]는 indicator function으로 해당 클래스에 속할때만 loss를 계산
 가 outlier에 대해
가 outlier에 대해 보다 덜 민감하기 때문에
보다 덜 민감하기 때문에 을 사용
을 사용
- Fast R-CNN network는 근본이 같은 두 가지 output layers를 가짐
- 첫 번째 결과는,K+1 카테고리에 대한
 의 이산확률분포
의 이산확률분포
- p는 fully connected layer의 K+1 출력에 대해 softmax로 계산된다. (즉, 확률 / object (K) + background (1))
- 두 번째 결과는 bounding-box regressor이다. K 클래스에 대해 index k로
 표현
표현
- parameter 설명

- Hierarchical sampling
- Fast R-CNN은 역전파를 통해 네트워크 모든 가중치를 학습



- Truncated SVD
- SVD : 매우 많은 피처를 가진 고차원 행렬을 저차원 행렬로 분리하는 행렬 분해 기법. 원본 행렬에서 잠재된 요소를 추출하기 때문에 토픽 모델링이나 추천 시스템에 활발하게 사용
- SVD는 m x n 크기의 행렬 A를 다음과 같이 분해하는 것을 의미
- m x n 크기의 행렬 A는 m x m 크기의 행렬 U와 m x n 크기의 ∑ 그리고 n x n 크기의 Vt로 나눔 (행렬 V의 전치 행렬(Transpose) = Vt)
- 행렬 U와 V에 속한 벡터를 특이 벡터, 모든 특이 벡터는 서로 직교하는 성질을 가집니다. ∑는 직사각 대각 행렬이며, 행렬의 대각에 위치한 값만 0이 아니고 나머지 위치의 값은 모두 0
- ∑의 0이 아닌 대각 원소값을 특이값
- m<n 이면 위 그림 , m>n 이면 아래 그림처럼 분할
- A = U * ∑ * Vt를 자세히 살펴보면
- U는 $AA^T$를 고유값 분해해서 얻은 직교 행렬, V는 $A^TA$를 고유값 분해해서 얻은 직교 행렬
- 직교 행렬
- 행렬 A와 A의 전치 행렬을 곱했을 때 단위 행렬이 된다면, A를 직교 행렬
- 즉, A의 전치 행렬이 역행렬인것

- 고유값 분해
- 정방 행렬 A를 선형 변환으로 봤을 때, 선형 변환 A에 의한 변환 결과가 자기 자신의 상수 배가 되는 0이 아닌 벡터를 고유벡터, 이 상수배 값을 고유값이라고 함
- 정방 행렬 : 같은 수의 행과 열을 가지는 행렬을 의미, 가로 세로 3x3, 2x2 같이 같은것
- 고유 벡터는 정방 행렬에 대해서만 정의됩니다. 다시 말해, 정방 행렬 A에 대해서 Av= λv 를 만족하는 0이 아닌 열벡터 v 를 고유 벡터, 상수 λ를 고유값
- 고유벡터, 고유값 설명

- 정방 행렬 A를 선형 변환으로 봤을 때, 선형 변환 A에 의한 변환 결과가 자기 자신의 상수 배가 되는 0이 아닌 벡터를 고유벡터, 이 상수배 값을 고유값이라고 함
- 직교 행렬
- U는 $AA^T$를 고유값 분해해서 얻은 직교 행렬, V는 $A^TA$를 고유값 분해해서 얻은 직교 행렬


- SVD는 m x n 크기의 행렬 A를 다음과 같이 분해하는 것을 의미
- SVD : 매우 많은 피처를 가진 고차원 행렬을 저차원 행렬로 분리하는 행렬 분해 기법. 원본 행렬에서 잠재된 요소를 추출하기 때문에 토픽 모델링이나 추천 시스템에 활발하게 사용
- 위 식에서 열 벡터 **v**에 행렬 A를 곱하는 것이 열 벡터 v에 선형 변환 A를 한것. (Av는 v라는 열 벡터에 선형 변환 A를 해주었다는 뜻, v라는 열벡터에 선형 변환 A를 해준 결과가 열 벡터 v의 상수 배(λ)와 동일하다면 → 선형 변환 A에 대하여 v
는 고유 벡터, λ는 고유값 )
- A**v** = λ**v**이 만족한다는 것은 벡터 **v**에 대해 선형 변환 A를 해주었을 때, 벡터 **v**의 방향은 변하지 않고 크기만 변했다는 뜻 (보통 벡터에 선형 변환을 수행하면 방향이 바뀜, 하지만 선형 변환을 했음에도 벡터 v의 방향이 바뀌지 않고 크기만 변했다면, 그리고 변한 크기가 원래 벡터의 λ배라면 그 λ가 고유값, v는 고유벡터 )
- 선형 변환 전
- 선형 변환 후
- 벡터의 색상은 파란색,분홍색,빨간색 총 3가지
- 빨간색은 벡터는 선형 변환후 방향과 크기 모두 변함 → 고유 벡터가 아님
- (파란색 벡터,분홍색 벡터)는 선형 변환후에도 방향이 그대로, 크기 변함 → 고유벡터
- 이때 고유값은 증가한 벡터의 크기 비율
- 고유값 분해 설명
- 행렬 A의 고유값을 λi, 고유벡터를 **v**i, i = 1, 2,..., n
- 식 정리하면
- 행렬 A의 고유 벡터들을 열 벡터로 하는 행렬을 P, 고유값을 대각원소로 가지는 대각 행렬을 Λ라 하면 다음 식이 성립
$$
AP = PΛ,
A = PΛP^{-1}
$$
- 이를 행렬 A에 대한 고유값 분해 (P는 고유 벡터들을 열벡터로 하는 행렬이며, Λ는 고유값을 대각원소로 가지는 대각 행렬입니다. 즉, 행렬 A를 고유 벡터와 고유값으로 분해한 것)
- 특징
- 대칭 행렬은 모두 고유값 분해가 가능
- U와 V에 속한 열 벡터를 특이 벡터
- U에 속한 벡터를 Left Singular Vector, V에 속한 벡터를 Right Singular Vector 라고 함
- ∑는 m x n의 직사각 대각 행렬(대각 행렬의 대각 성분은
혹은
의 고유값들에 루트를 씌워준 값으로 구성)
- 대칭 행렬은 모두 고유값 분해가 가능 + 직교 행렬로 분해 가능, 그래서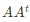
와
는 모두 대칭 행렬이므로 고유값 분해 가능
->
이렇게 분해 가능
-
의 대각 원소 값은
의 고유값 이며, U는
의 고유 벡터들로 구성된 행렬입니다. 마찬가지로 V는
를 고유값 분해해서 얻은 행렬입니다.
의 대각 원소 값은
의 고유값이며, V는
의 고유 벡터들로 구성된 행렬
- 정리
- SVD는 특이값 분해라고 하며, 행렬 U와 V에 속한 벡터를 특이 벡터, 모든 특이 벡터는 서로 직교하는 성질을 가짐
- ∑는 대각행렬이며, 행렬의 대각에 위치한 값만 0이 아니고 나머지 위치의 값은 모두 0, ∑의 대각 원소 값이 바로 행렬 A의 특이값
- A의 특이값은
혹은
의 고유값의 루트 값과 같음
- CNN 거쳐 생성된 feature map과 FC layer 사이에 위치
- Fast R-CNN 모델은 detection 시, RoI를 처리할 때 fc layer에서 많은 시간소요가 큼
- 논문에서는 detection 시간을 감소시키기 위해 Truncated SVD(Singular Vector Decomposition)을 통해 fc layer를 압축하는 방법을 제시
- Full SVD, Truncated SVD
- 행렬 A를 m x m 크기인 U, m x n 크기인 ∑, n x n 크기인 Vt 로 특이값 분해(SVD)하는 것을 Full SVD
- 실제로는 ∑의 비대각 부분과 대각 원소 중 특이값이 0인 부분을 모두 제거, 제거된 ∑에 대응되는 U와 V 원소도 함께 제거해 차원을 줄인 형태로 SVD를 적용하는 방식을 사용 —> Truncated SVD
- Truncated SVD
- ∑의 대각 원소 중 상위 몇 개만 추출하고 여기에 대응하는 U와 V의 원소도 함께 제거해 차원을 줄인 것
- ∑의 대각 원소 중 상위 t개만 추출하면 위와 같은 모양
- 이렇게 하면 행렬 A를 상당히 비슷하게 근사하는것이 가능
- 논문에서는 Truncated SVD를 통해 detection 시간이 30% 정도 감소 되었다고 함Fast R-CNN 전체 과정 요약


- R-CNN 에서와 마찬가지로 Selective Search를 통해 RoI를 찾음
- 전체 이미지를 CNN에 통과시켜 feature map을 추출
- Selective Search로 찾았었던 RoI를 feature map크기에 맞춰서 투영
- 투영시킨 RoI에 대해 RoI Pooling을 진행하여 고정된 크기의 feature vector 생성
- max-pooling을 통해 피처 맵 구함, RoI 풀링 계층은 고정된 크기의 feature vector 추출
- feature vector는 FC layer를 통과한 뒤, 두 단계로 나뉨
- 하나는 softmax를 통과하여 RoI에 대해 object classification을 수행
- 클래스 개수가 K 개라고 할 때, softmax 결괏값 개수는 총 (K+1) 개입니다. +1은 배경임
- bounding box regression을 통해 selective search로 찾은 box의 위치를 조정
- classification + bounding box regression 후 nms 적용해서 최종 객체 인식
이런 과정을 가진 Fast R-CNN은 multi-task loss를 가지고 end-to-end 훈련을 수행
반응형
'Study > Paper' 카테고리의 다른 글
| YOLO 논문 리뷰 (2) | 2024.07.22 |
|---|---|
| Faster R-CNN 논문 리뷰 (0) | 2024.07.22 |
| SSD 논문 리뷰 (0) | 2024.07.09 |
| R-CNN 논문 리뷰 (1) | 2024.07.05 |
| HOG, SIFT Object detection 발전과정 (2) | 2024.07.03 |